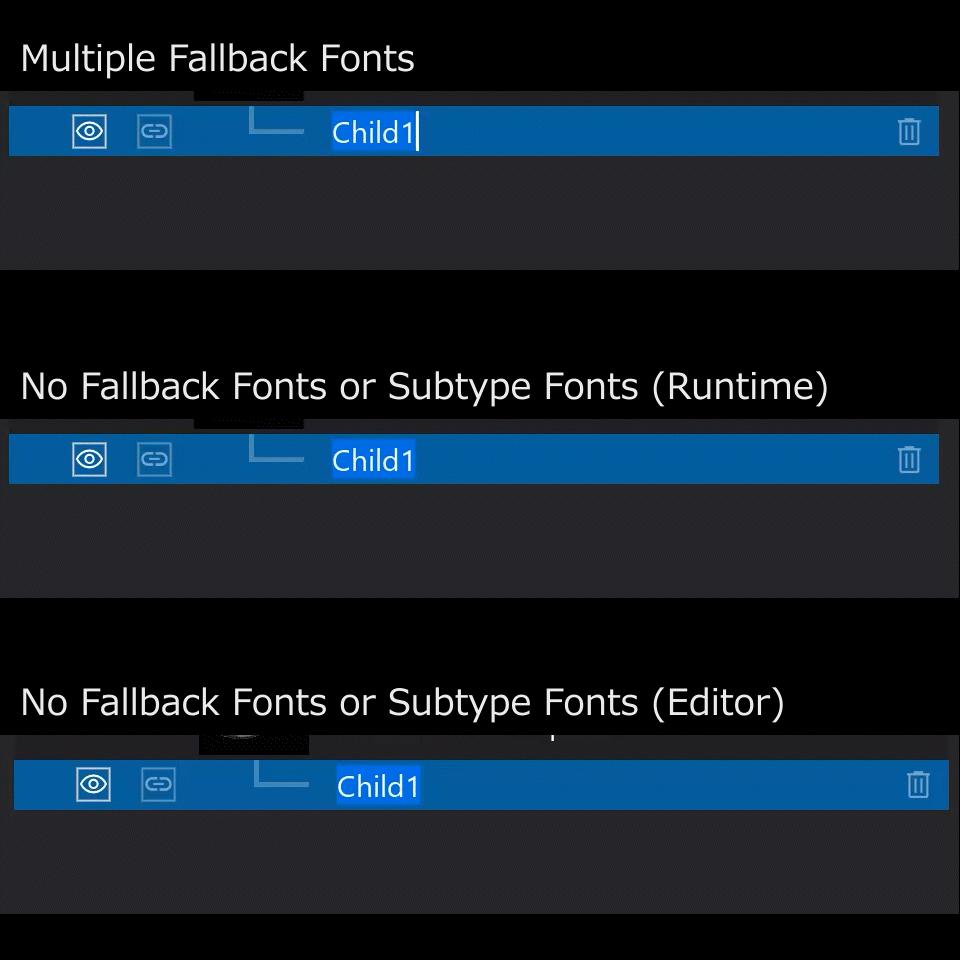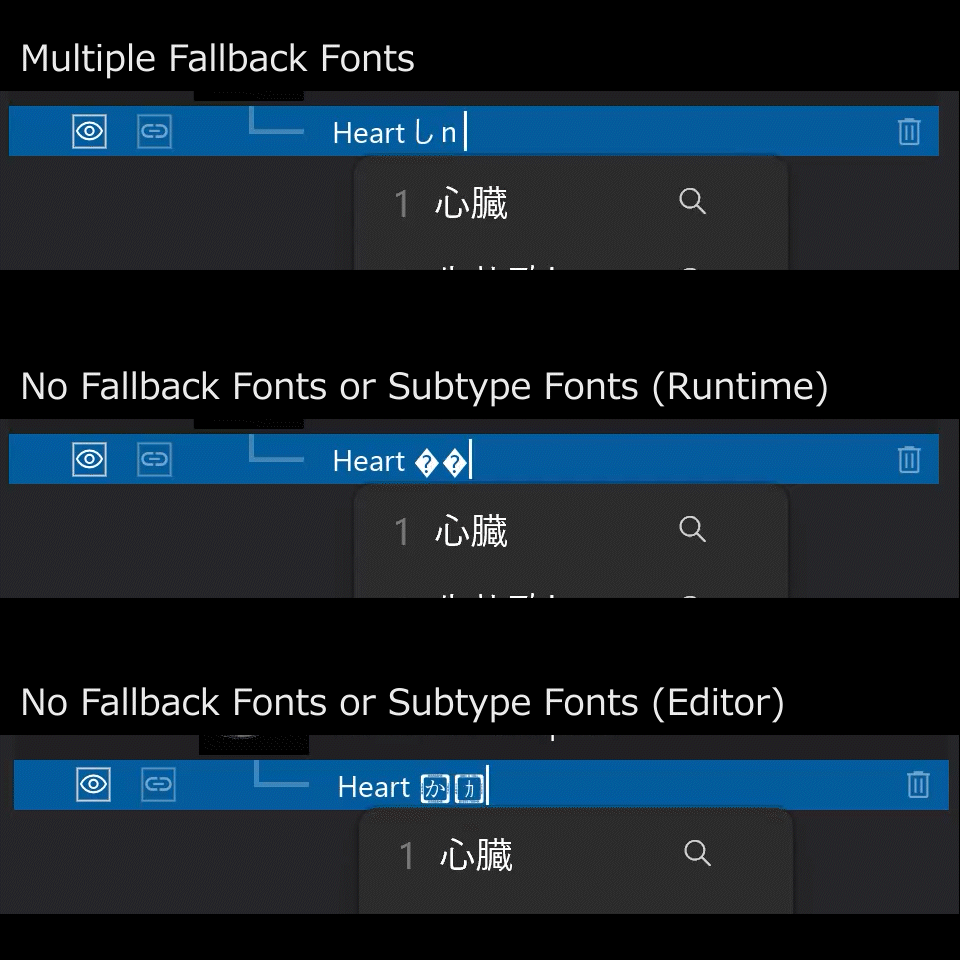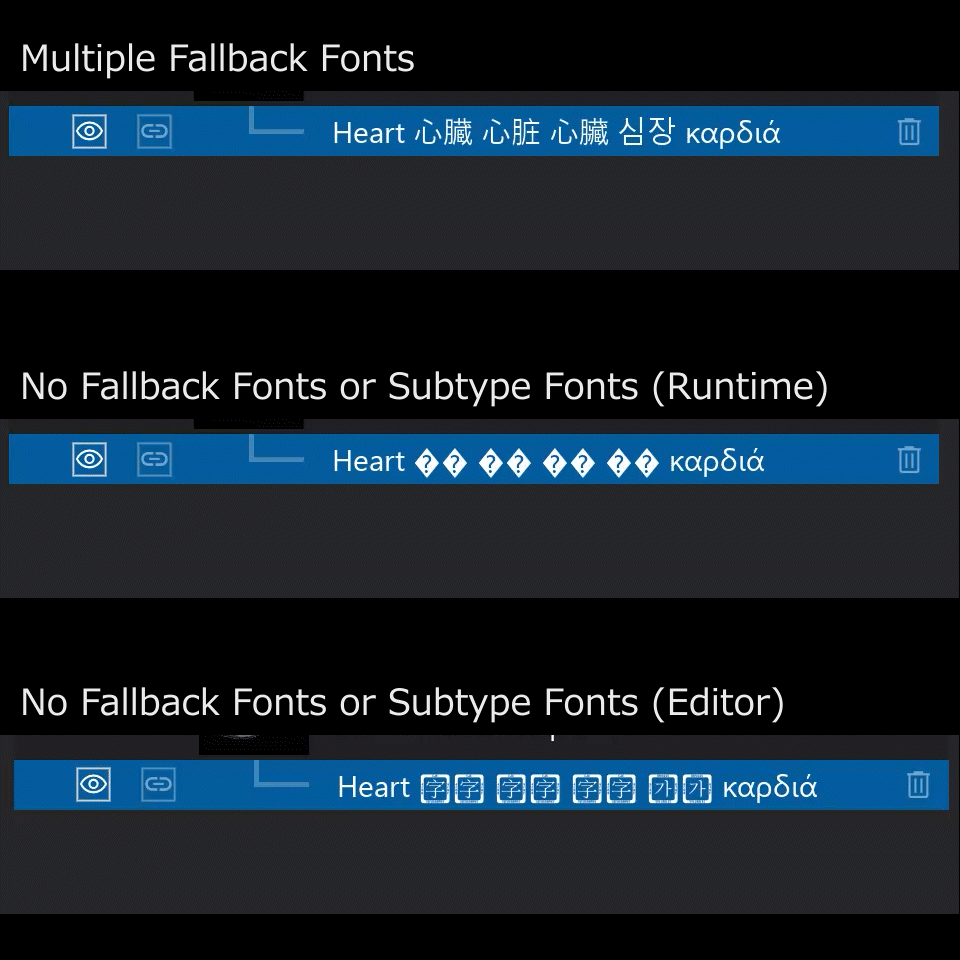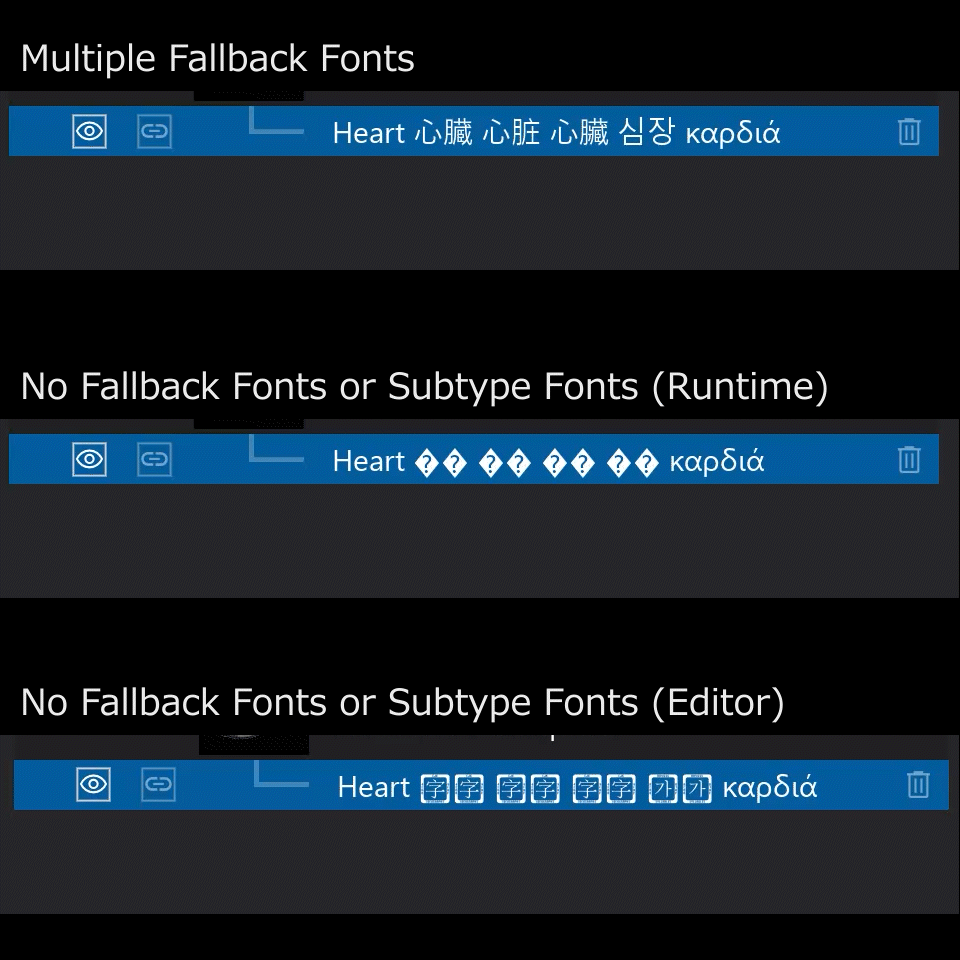
Unreal Engine 5の文字入力はWindows標準のDirectWriteやGDIではなく、Unreal Engine特有の仕組みで実現されています。マルチプラットフォーム対応のゲームエンジンですので、OSの違いでフォントの選ばれ方が変わってしまわないように設計されているのだと思います。
予めフォントをアプリ内に含めておくのではなく、ランタイム時に動的にフォントファイルを読み込んで文字を表示するために、Unreal Engineではコンポジットフォント(Composite Font, FCompositeFont)という仕組みが用意されています。
コンポジットフォントの使い方は、下記の英語記事で非常にわかりやすく解説されています。
Unreal Composite Fonts: making a font that supports all the game languages
コンポジットフォントは
- 単一のDefaultTypeface (FTypeFace)
- 複数のSubTypefaces (TArray<FCompositeSubFont>)
- 単一のFallbackTypeface (FCompositeFallbackFont)
から成り、SubTypefacesは使用する文字範囲(UNICODEでのcode ranges)を必ず指定する必要があり、加えてCultures (en;jaなど)をオプションで文字列として登録しておくと、アプリ側で指定した言語設定と同じCultureだった場合には当該のSubTypefacesが優先的に選択されます。
複数のSubTypefacesでcode rangesが被ってしまった場合にはいずれか1つのSubTypefaceだけが選択されるようです。FCompositeFont, FCachedCompositeFontData, FFontDataあたりの実装コードを読み解いていくと理解出来ます。
ゲームのUIの文字など、予め表示したい文字が決まっており、各国の言語に合わせてローカライゼーションを行いたいような場合にはおそらく現状のFCompositeFontの実装で問題無いのだとは思いますが、SEditableTextBoxのようにユーザが自由に文字を入れられる状況だったり、弊社で開発しているViewtifyのようにあらゆる国の人名が表示され得るような状況では、FCompositeFontの設計ではどうしても限界があります。最大の原因は、FallbackTypefaceに単一のフォントファミリーしか登録出来ないことです。
例えば日本語環境のPCでは、基本的に英語でUIが表示されるアプリではSegoe UIのようなフォントをDefaultTypefaceで指定しつつ、漢字やひらがなが混じる場合を考えて、Yu Gothic UIのような日本人にとって見慣れたフォントで漢字を表示するためにSubTypefacesに加えることを考えるでしょう。しかしここで早速問題が発生します。日本語フォントのcode rangesをどうすれば良いのでしょうか?
Hiragana [0x3040 – 0x309F]
Katakana [0x30A0 – 0x30FF]
などは含めるとして、漢字の集合体である
CJK Unified Ideographs [0x4E00 – 0x9FFF]
も必須ですが、ここには中国語の簡体字や繁体字も含まれます。残念ながらYu Gothic UIは主に日本で使われる漢字しかカバーしていません。となると、FallbackTypefaceにMicrosoft JhengHei UIやMicrosoft YaHei UIなどを入れておく必要がありますが、FallbackTypefaceには1つしか登録できませんのでどちらかを選択する必要があります。
一応これで大抵の日本語と中国語は表示出来ますが、CJK Unified Ideographs Extension B – Fあたりはさらに別のフォントでないと表示出来ないことのほうが多いでしょう。ですがこれはSubTypefacesにcode ranges付きで指定してやればまだ何とかなります。
頻度は少ないかもしれませんが、入力する文字に絵文字やシンボルが入ることも考えられます。まずはSegoe UI Emojiのような絵文字フォントを試した上で、非対応ならSegoe UI Symbolで表示したい、ということも少なくないと思いますが、単一のFallbackTypefaceしか指定できないためどうすることも出来ません。WindowsのAPIなどを用いて、フォントが対応しているcode rangesを全て調べ上げた上で重複のないようにcode rangesを細かく指定すれば出来なくもないですが、配列が膨大になってしまい現実的ではありません。FallbackTypefaceを複数登録出来れば、
SubTypefaces → DefaultTypeface → (code rangesの指定の無い複数の)FallbackTypefaces
の順に試すことが出来ますので、FallbackTypfacesに例えば中国語フォント、シンボルフォント、絵文字フォント、CJK Unified Ideographs Extension B – Fの滅多に出てこない文字に対応したフォントあたりを登録しておけば、ほとんどの場合に表示出来そうです。
…というわけで非ゲームアプリでは複数のFallbackTypefacesが必須となることも少なくないと考えられるため、エンジン改造で対応しました。
こんなマニアックな改造が公式に取り込まれるかどうかはわかりませんが、Pull Requestを作成しました。
Pull request: Support multiple fallback fonts in FCompositeFont.
なお、上記Pull Requestではエディタ上で設定出来るフォントエディタにまでは対応しておらず、C++で直接FCompositeFontを作る場合のみの対応になっています。ご参考になれば。
…いやはや、本当はDICOM画像で英語以外の言語でそれぞれの文字コードで書かれた患者名や施設名を正しく扱えるように諸々手を付けたのですが、少なくとも日本語においてはDICOMでは漢字はShift-JISではなくJISコードで書かれていなければいけないのに、規約違反でShift-JISで書かれているものが大量にあり、無理やり正しく扱えるようにするだけでも大変だったのですが、今度はWindows用に正しくUTF-16に変換された文字をUnreal Engine上で表示するのにさらに一苦労…というだいぶ辛い作業で、ほぼ丸一ヶ月費やしてしまいました…。生成AIに適宜助けてもらいながらどうにか出来ましたが、巷ではこれまで1年かかったコード実装がAIフル活用であっという間に出来てしまったというようなニュースも多い中で一ヶ月かかってしまったのは、私が全く生成AIを使いこなせていないからなのでしょう…。